Летом 2011 года я создал целый рядсобственных модификаций получившего широкую известность калькулятора
DIY Dodecad гениального грека Диенека Понтикоса. К моему приятному удивлению, за прошедшее время калькулятором успело воспользоваться несколько тысяч людей, некоторые из которых даже выложили свои результаты в Интернете. Разумеется, многие также разместили и свои собственные интерпретации полученных результатов. Некоторые из приведенных в комментариях интерпретации выделялись (в хорошем смысле этого слова) высоким академическим уровнем, но мне попадались и такие комментарии, при чтении которых становилось понятно, что авторы не только не понимают принципов и сути парадигмы анализа, предложенного Понтикосом, но и — что гораздо хуже — выдавали свои фантазии за действительности. Особенно часто мне попадались подобные фантастические рассуждения в русскоязычном секторе Интернета.Пример такого невежества можно найти в рассуждениях само-провозглашенного академика ДНК-генеалогии Анатолия Клесова:
Но и в этом случае различия все равно будут между русскими и монголами. Качественно и как-то полуколичественно его можно рассматривать, но не в виде профанации, как это делает Понтикос. Более того, это рассмотрение – если правильно – надо проводить не на выбранных маленьких фрагментах, а действительно по всему геному. На маленьких фрагментах будут вылезать отдельные особенности – то присущие в основном, например, гаплогруппам Y-I2 и мтДНК-Н, то кому-то еще. И это еще будет зависеть от разрешения, которые и обозначают индексами К=4, К=8 и другими. То есть берут маленький фрагмент генома, да еще с малым (или бóльшим) разрешением, стягивают в точку, и все равно получают в целом ерунду. Но для коммерции годится. Годятся для коммерции и вот такие, в частности, «открытия» того же Понтикоса: Перевод: Интересно то, что европейская популяция показывает присутствие американских индейцев, что показывает и f-статистика, и она же показывает присутствие компонента с Сардинией. Как видим, Понтикос уже забыл, что названия им придуманы как попало, и уже придает им абсолютные значения. Про Сардинию Понтикос уже вошел в состояние экзальтации. Он придает Сардинии некую пра-европейскую значимость, на основании, конечно, этой ерунды с «геномом», который анализирует как хочет. Пример – он трубил по всему свету, что Отци, «ледовый человек», имел геном «Сардинии». Однако только что опубликована статья о том, что Отци – никакая не Сардиния, а типичная Центральная Европа. Ну, и что делать будем? Понтикос, с его страстным желанием сенсаций, каждый раз наступает на одни и те же грабли. Впрочем, фарс продолжается. Теперь тем же занялся некто российский Веренич, а именно тоже насчитывает «польскую компоненту», пользуясь подходом своего гуру-Понтикоса.
Принимая во внимание вышесказанное, я решил просветить русскоязычную общественность относительно каким образом создавалось один из вышеупомянутых калькуляторов-модификаций (а именно World22, поскольку я считаю ее самой удачной модификацией). Тем более что в ходе многочисленных экспериментов было убедительно показано, что результаты моего калькулятора являются наиболее точными для выходцев из Восточной Европы. В просветительских целях я перевел
одно из сообщений своего англоязычного блока на русский язык. Надеюсь, что по прочтению этого текста, у читателя сложится более полное представление о принципах этно-популяционного анализа с помощью DIY калькуляторов.
Предварительные замечания
Как вы возможно знаете, MDLP блог не обновлялся с февраля 2012 года. Полгода тому назад я пообещал себе, что я не буду писать новые сообщения на MDLP блоге до те пор пока я не напишу краткую научный отчет о проделенной работе. Так как приоритеты завершения научной работы были важнее рутиного обновления блога, то в связи с нехваткой времени, я был не в состоянии продолжать обновление блога на регулярной основе, в связи с нехваткой времени, я должен был внести изменения в свой исследовательский график. Поэтому я решил воздерживался от размещения новых данных на блоге в течение нескольких месяцев, фокусируясь на более важных вопросах. Несмотря на все ограничения, я продолжал втайне работать на проектом MDLP, сбором необходимых данных и выполением различных ‘геномных’ экспериментов в целях достижения своей конечной цели. Однако с течением времени, некоторые результаты секретных экспериментов с новыми полногеномными популяционными выборками и инструментами в конечном итоге просочились в Интернет, порождая огромный интерес к моему проекту. После выпуска новой версии моей собственной модификации DIYDodecad калькулятор на сайте
Gedmatch.com, я был буквально завален письмами пользователями сервиса Gedmatch.com.
Тогда я осознал свою основную стратегическую ошибку, которая заключалась в отсутствии подробной документации к выпущенными мной данными и результатам анализа, и почувствовал себя обязанным разместить более подробные разъяснения. Очевидно, я начну новую серию публикацию в своем блоге, которая будет тесным образом связанна с теми аспектами моей работы, которая наиболее интересует общественность, то есть с калькулятором MDLP World22.
Основы отбора референсных популяций калькулятора MDLP World22.
Кроме того, я отобрал произвольным образом по 10 сэмплов (или максимальное количество доступных сэмплов в тех случаях, когда общее число сэмплов в популяции было меньше 10) от каждой европейской страны, представленной в панеле базе данных
POPRES. Наконец, для того чтобы оценить степень корреляции между современным и древним генетическим разнообразием населения Европы, я также включил в выборку образцы древней ДНК
Эци (
Keller et al. (2012)) , образцы житлей шведского неолита Gök4, Ajv52, Ajv70, Ire8, STE7 (
Skoglund et al. (2012)) и 2 образца La Braña — останков мезолитических жителей Пиренейского полуострова (
Sánchez-Quinto et al.(2012)).
Затем я добавил 90 образцов — анонимизированных данных — участников моего проекта. После слияния вышеупомянутых наборов данных и истончения набора SNP с помощью особой команды PLINK, я исключил SNP-ы с более чем 1% минорных аллелей. После чего я отфильтровал дубликаты, лиц с высоким уровнем общих по происхождению идентичных сегментов (IBD). В качестве критерия фильтрации были использованы расчеты IBD в Plink, где IBD представлена как средняя доля аллелей общих между двумя людьми по всем анализируемым локусам. Затем я удалил из выборки лиц с высоким коэффициентом предпологаемого родства (коэффициенты родства были вычислены в программном обеспечении
King). Для получения более стабильных результатов, я также отфильтровал сэмплы с более чем 3 стандартными отклонениями от средних данных по популяции. Поскольку коэффициент родства может быть надежно определен с помощью оценки HWE (ожидания, вытекающего из закона
Харди-Вайнберга) между SNP-ами с той же базовой частотой аллелей, то SNP-ы с существенным отклонением (
p < 5.5 x10
−8) от ожидания Харди-Вайнберга были удалены из объединенного набора данных. После этого я выделил те SNP-ы, которые присутствовали в чипах Illumina / Affymetrix, и затем произвел фильтрацию снипов на основе расчетов степени неравновесного сцепления (в этой я использовал хромосомное ‘окно’ размером в 50 базовых пар, с шагом 5 базовых пар и пороговым значением уровня сцепления R ^ 2, равным 0,3).
По окончанию этой сложной последовательности операций, я получил окончательноый набора данных, который включал в себя 80 751 снипов, 2516 человек и 225 референсных популяций.
Анализ этно-популяционного адмикс
В ходе следующенго этапа, окончательный набор данных по референсным популяциям (которые я храню в linkage-формате PLINK) был обработан в программе
Admixture. Во время выбора подходящей модели проведения теста на этно-популяционный адмикс, я столкнулся с крайне трудной задачей: как было показано в профильных научных исследованиях (
Patterson et al.2006) количество маркеров, необходимых для надежной стратификации популяций в анализе обратно пропорциональна генетическому расстоянию (фСТ) между популяциями. Согласно рекомендациям пользователей программы Admixture, считается что примерно 10 000 генетических SNP-маркеров достаточно для выполнения интер-континентальной GWAS -коррекции обособленных популяций (например, уровень дивергенции между африканскими, азиатскими и европейскими популяциями FST > 0.05), в то время как для аналогичной коррекции между внутриконтинентальными популяциями требуется более чем 100000 маркеров (в Европе, например, ФСТ < 0.01). Для повышения точности результатов Admixture я решил использовать метод, предложенный Dienekes. Этот метод позволяет
преобразовать частот аллелей в «синтетические» индивиды (см. также
пример Зака Аджмала из проекта HarappaDNA). Идея метода довольно проста: сначала необходимо запустить unsupervised анализ Admixture с целью вычисления частот аллелей в так называемых предковых компонентов, а затем на основании аллельных частот сгенерировать «фиктивные популяции». Именно эти фиктивные популяции и индивиды будут использоваться в ходе чистых референсов в ходе последующего анализа этно-популяционного анализа.
Впрочем, как и любой другой исследователь, работающий над четким решением проблемы этно-популяционного адмикса, я вынужден считаться с ограничениями этого подхода. Хотя я и отдаю себе отчет в существовании явных методологических подвохов в использовании смоделированных искусственных индивидов для определения адмикса в реальной популяции, я все же скорее склонен согласиться с Понтикосом, которые считаeт полученных в ходе аллельно-частотного моделирования «фиктивных индивидов» лучшей аппроксимацией древних генетических компонентов мирового народонаселения.Как бы то не было, моделирующий подход, предложенный Диенеком и Заком, сослужил свою хорошую службу, поскольку были мной были получены значимые результаты в ходе создания нового калькулятора. Сначала я произвел unsupervised Admixture (при значении К = 22, т.е 22 кластера частот аллель или предковых компонентов). По выполнению анализа нами были получены оценки коэффициентов адмикса в каждой из этих 22 аллельных кластеров, а также частоты аллелей для всех SNP-ов в каждой из 22 родовых популяций.
Затем я использовал мнемонические обозначения для каждого компонента (имена для каждого из компонентов выведены в порядке их появления). Нужно помнить, что обозначения этих компонентов носят скорее мнемонический условный характер:
Pygmy
West-Asian
North-European-Mesolithic
Tibetan
Mesomerican
Arctic-Amerind
South-America_Amerind
Indian
North-Siberean
Atlantic_Mediterranean_Neolithic
Samoedic
Proto-Indo-Iranian
East-Siberean
North-East-European
South-African
North-Amerind
Sub-Saharian
East-South-Asian
Near_East
Melanesian
Paleo-Siberean
Austronesian
Вышеупомянутые частоты аллель, вычисленные в ходе unsupervised (безнадзорного) анализа (Admixture K = 22) объединенного набора данных, были затем использованы для симуляции синтетических индивидов, по 10 индивидов на каждую из 22 предковых компонент. Это симуляционное моделирование проводилось с помощью PLINK команды -simulate Когда моделирование было закончено, я сделал визуализацию расстояния между симулированными индивидами с использованием многомерного масштабирования.

На следущем этапе, я включил группу смоделированных индивидов (220 индивидов) в новую эталонную популяцию. После чего я запустил новый анализ А, на этот раз в полном «поднадзорном» режиме для K = 22, причем полученные в ходе симуляционного моделирования фиктивные популяции фиктивных индивидов использовались в качестве новых референсных эталонных групп. На конвергенцию 22 априорно заданых предковых компонентов было затрачено 31 итераций (3 7773,1 сек) с окончательным loglikelihood: -188032005,430318 (ниже приведена таблица значений Fst между расчетными ‘предковыми’ популяциями):
Приведенная выше матрица Fst дистанций была использована для определения наиболее вероятной топологии NJ-дерева всех 22 предковых компонентов ( примечание: в качестве outgroup-таксона использовался South-African component). Индивидуальные результаты ‘поднадзорного’ анализа этно-популяционных миксов (в формате Excel) для участников проекта были загружены на
GoogleDrive. MDLP World22 DIYcalculator
Выходные файлы «поднадзорного» анализа Admixture K=22 (средние значения коэффициентов адмикса в референсных популяциях и значения Fst) были использованы для разработки новой версии DIYcalculator MDLP, который более известен под кодовым названием «World22» (онлайн версия доступна разделе Admixture-утилит на сервисе Gedmatch в рамках проекта MDLP). Как я уже упоминал выше, MDLP DIYcalculator работает на коде Dodecad DIY calculator (c)
Dienekes Pontikos.
В свою очередь, реализованная на сервисе Gedmatch модификация DIYcalculator ‘World22’ комбинирована с Oracle ‘World22’ MDLP, который также работает на коде Диенека и Зака Аджмала (
Хараппа/DodecadOracle). Программа «Oracle» работает в двух режимах. В режиме single population программа определяет ближайщие (к анализируемому геному) референсные популяции калькулятора Word22. В смешанном режиме, Oracle рассматривает все пары населения, и для каждой из пар вычисляет минимальное Fst-взвешенное расстояние между парой и анализируемым геномом, а также коэффициенты сходства.
Предковые популяции (т.е. полученные в ходе симуляционное моделирования популяции — см. выше) обозначены в результатах Oracle суффиксом anc, в то время реальные современные и древние популяции обозначены суффиксом der.
Если у Вас возникли проблемы с пониманием/интерпретацией результатов Oracle и DIYcalculcator, то я настоятельно рекомендую обратится к соответствующим темам в блогах Dodecad и НаrappaWorld . Я полагаю, что не имеет особого практического смысла заново изобретать велосипед и слово в слово повторять то, что уже было написано более компетентными в этом вопросе людьми.
Что представляют собой компоненты MDLP World-22?
Один из наиболее частых вопросов, которые задают мне пользователи калькулятора, напрямую касается практической интерпретации референсных популяций и предковых компонентов в моих калькуляторах K = 12 и World-22 анализов в виду. Чуть выше по тексту я уже привел часть ответа на этот вопрос , но — как гласит старинная китайская пословица — одна картинка стоит десять тысяч слов. Вот почему я решил визуализировать компоненты на поверхности земного шара путем отображения коэффициентов адмикса. Избегая излишних премудростей, я воспользовался
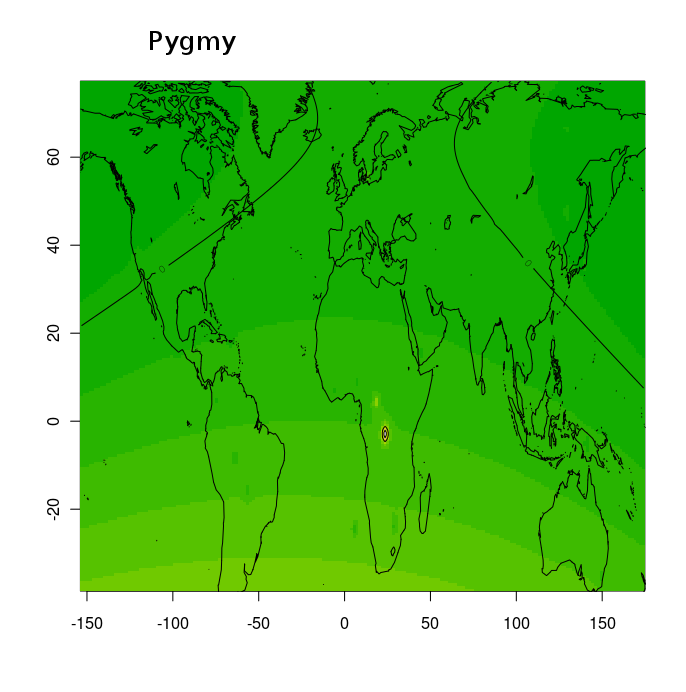
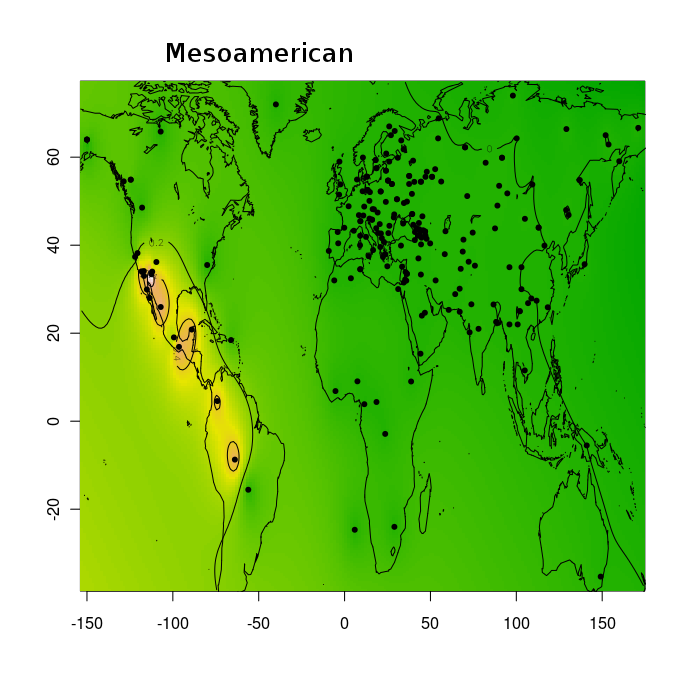
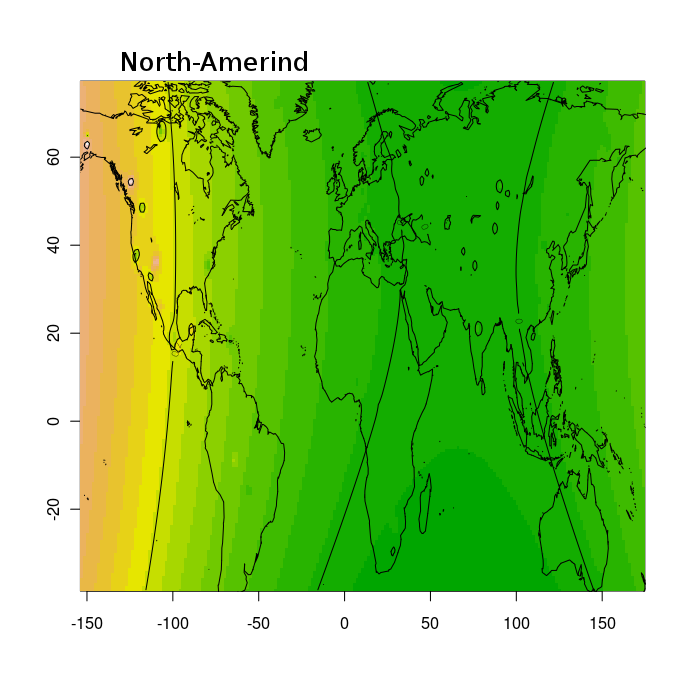
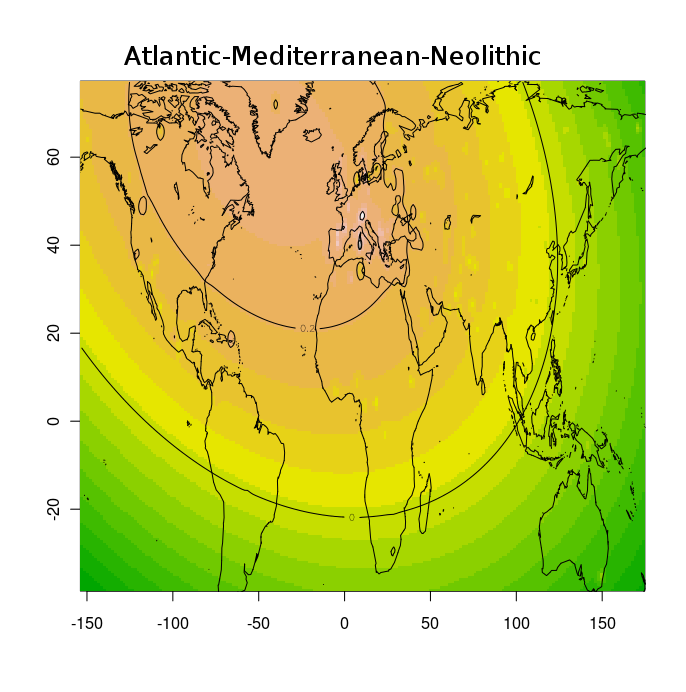
готовым рецептом Франсуа Оливье, который предложал использовать графическую библиотеку статистического программного обеспечения R для отображения пространственной интерполяции коэффициентов адмикса (Q матрица) в двух измерениях (где пространственные координаты записываются как географические долгота и широта). Благодаря этому решению, мне удалось создать по 2 контурные карты на каждый из предковых компонентов.Pygmy
(модальный компонент в популяциях африканских пигмеев Biaka и Mbuti)
West-Asian (бимодальный компонет с пиком на Кавказе и юго-восточной части Ирана, приблизительно идентичен компонентам Caucasian/Gedrosia Диенека Понтикоса)
North-European-Mesolithic (локальный архаичный компонент с пиком в популяции древних европейских жителей Иберийского полуострова La_Brana и современной популяции саамов).
Tibetan (Indo-Burmese) component (Гималаи-Тибет)
Mesomerican (главный генетический компонент у мезоамериканских америндов)
North-Amerind (нативный компонент северо-американских америндов)
South-Amerind (нативный компонент южно-американских индейцев)
Atlantic-Mediterranean-Neolithic (доминируюший компонент в западной и юго-западной Европе)
Контурные карты прочих компонентов можно скачать здесь.