Сергей Козлов
Палеоевропейцы из работы Haak et al, 2015 в свете анализа на IBD-сегменты.
Обновлено 21.03.2015
В феврале произошло событие, которое многие геномные блоггеры с нетерпением ожидали на протяжении большей части предыдущего года — на сервере Bioarxiv был размещен препринт статьи Haak et al с исследованием множества (преимущественно европейских) палеогеномов. Настолько качественного и подробного среза генетической истории европейцев мы еще не видели. Вадим Веренич уже разместил свой отзыв на работу, присовокупив к нему результаты собственных экспериментов и размышлений. Из его заметки можно составить прекрасное впечатление о статье.
Как это обычно и бывает, сообщество геномных блоггеров осталось не вполне удовлетворено полнотой предоставленной информации, и (повторюсь) с нетерпением ожидало возможности наложить свои руки на новые палеогеномы из статьи. Для этого пришлось дождаться официального выхода работы, и вот, наконец, момент настал. В первую очередь мне было интересно провести сравнение аутосомных IBD (или псевдо-IBD) сегментов с современными выборками и удостовериться — кто же все-таки в наибольшей степени является потомками людей, принадлежавших к исследованным археологическим культурам? Конечно, другие виды анализа тоже необходимо провести, но это сделают и без меня. К тому же об их результатах можно было догадаться из информации, опубликованной в статье (и эти догадки действительно подтвердились).
К сожалению, первая попытка оказалась неудачной — опубликованные на страничке лаборатории Райха геномы были полностью гаплоидными. Для того, чтобы сблизить условия анализа прочитанных с разным качеством палеогеномов, авторы статьи случайным образом выбирали один аллель для каждого снипа и далее использовали только его. Разумеется, все IBD-сегменты при этом оказались разрушены. Однако проблему удалось обойти при помощи утилиты Феликса Чандракумара, преобразующую BAM-файлы в аналоги аутосомных файлов формата FTDNA. Лишь меньшая часть из обработанных геномов пригодна для IBD-анализа, но и прочитанных с удовлетворительным качеством достаточно много. Для этой заметки использованы следующие палеогеномы:
1) «Восточных охотников-собирателей», или EHG, представляет «оленеостровец» I0061 Karelia_HG Yuzhnyy Oleni Ostrov, Karelia 5500-5000 BCE . «Самарский» образец EHG слишком плохо прочитан.
2) «Самарских ямников» представляют I0443 Yamnaya Lopatino II, Sok River, Samara 3500-2700 BCE и I0231 Yamnaya Ekaterinovka, Southern Steppe, Samara 2910-2875 calBCE
3) Культура шнуровой керамики также представлена двумя образцами, это I0103 Corded_Ware_LN Esperstedt 2566-2477 calBCE и I0104 Corded_Ware_LN Esperstedt 2473-2348 calBCE (восточная Германия, земля Саксония-Анхальт)
4) От культуры колоколовидных кубков лишь один образец, это I0112 Bell_Beaker_LN Quedlinburg XII 2340-2190 calBCE (как и в случае КШК, земля Саксония-Анхальт)
5) Лучше всего обстоит дело с охватом неолитических земледельцев из культуры линейно-ленточной керамики, их целых четыре — I0054 LBK_EN Unterwiederstedt 5209-5070 calBCE , I0100 LBK_EN Halberstadt-Sonntagsfeld 5032-4946 calBCE, а также два ранее уже известных палеогенома — Stuttgart и NE1
Результаты по выборкам, представленным двумя или более образцами, усреднялись. Кроме этого, производилось нормирование результатов для каждой из пяти палеовыборок в пределах +- 10% с целью наилучшим образом попадать в диапазон карт и убрать влияние разницы в качестве прочтения. Конечно, это искусственное искажение данных, но все же, как мне кажется, оно скорее пошло на пользу, чем нанесло вред. В целом же карты получились качественными и наглядными. Думаю, что метод анализа на IBD-сегменты даже лучше подходит для палеогеномов, чем для наших современников.
«Оленеостровец» I0061 принадлежит к выборке, названной авторами EHG (Eastern Hunter-Gatherers). Это палеоевропейские охотники-собиратели северной части Восточной Европы, предположительно не затронутые позднейшим притоком генов с юга (от неолитических земледельцев и из других источников). И действительно, среди наших современников наибольшее количество пересечений с ним нашлось у северных восточноевропейцев — как говорящих на индоевропейских языках, так и уральцев. В первую очередь выделяются вепсы и северные русские из каргопольской выборки HGDP. Прибалтийская выборка, обычно проявляющаяся у восточноевропейцев наиболее ярко, на этот раз видна чуть слабее. Единственные, кто несколько выбивается из закономерности — поляки. Сложно сказать, случайность это, или же нет. Однако из-за этого отклонения польская выборка временами смотрится странно и на дальнейших «разностных» картах.
Оленеостровец (картинки можно увеличивать):

Обращает на себя внимание пятно в Средней Азии и северной Индии. Особенно интересна значительная разница между высшими и низшими кастами штата Уттар-Прадеш (на карте представлены обе выборки). Напрашивается версия, что это связано с приходом индоевропейцев с севера. Или же, как минимум, с приходом носителей R1a. Кстати, оленеостровец тоже принадлежал к этой Y-гаплогруппе (предковая ветвь R1a1).
Впрочем, как мне справедливо заметили, в северо-западную Индию было немало миграций и в более поздние времена. Например, «кшатрии» на севере считаются многими исследователями потомками переселенцев первого тысячелетия нашей эры.
Следующие на очереди — «ямники». В работе использованы образцы ямников из-под Самары, представляющие их крайний восточный вариант. Авторы статьи смоделировали их как 50% EHG / 50% современные армяне. Как будет показано далее, для этого есть некоторые основания. Однако с точки зрения предковых компонентов Admixture такая модель — далеко не лучший вариант, «южный» ямный компонент скорее связывается с чем-то в промежутке между Восточным Кавказом и Средней Азией. Как и предполагалось, он коррелирует с бимодальным компонентом, условно называемым Gedrosia. Исходя из современных максимумов, его исторический центр находится где-то в южном Прикаспии, возможно, восточнее. Судя по всему, он представляет собой результат смешения «ближневосточного» компонента ENF и ANE, поэтому теоретически исторического центра может и вообще не быть.
Самарские ямники:

В отличие от оленеостровца, «ямное» пятно более широко распределено по всей Европе, а Кавказ и Средняя Азия выделяются сильнее. Впрочем, лучше это смотреть на карте, отображающей разницу между ямниками и оленеостровцем. Не следует думать, что выборки, выделенные на разностной карте одним цветом, обязаны быть схожи между собой — просто разница их «расстояний» до I0443/I0231 и I0061 близка. И не забываем, что разностные карты в большей степени, чем одиночные, подвержены влиянию «шума» и случайных отклонений.
Разница между «оленеостровцем» и «ямниками». Красным цветом обозначено, у кого больше общих сегментов с первым, зеленым — со вторыми.

Как видно, наибольшая разница в пользу оленеостровца у представителей народов из уральской языковой семьи, причем тех, у кого силен «сибирский» вклад. Кроме жителей Западной Сибири, это марийцы (и родственные им тюрки-чуваши) в Поволжье, а также саами. Думаю, это неплохой довод в пользу ямников (или тесно связанной с ними группы), как распространителей индоевропейских языков. Наибольшая же разница «связь с ямниками» минус «связь с оленеостровцем» оказалась у уже упоминавшихся армян (и в целом зеленое пятно Кавказ-Малая Азия выражено сильнее всего). Таким образом, у армян хорошо выражены компоненты, имеющиеся у ямников, но отсутствующие у EHG. Но значит ли это, что модель «ямники=EHG+армяне» оптимальна? Я так не считаю. И при PCA-анализе, и при раскладке на компоненты Admixture мы видим, что «вторая половинка» должна быть где-то восточнее. На карте это проявляется в том, что взаимосвязь ямников с районом Пакистан-северная Индия (а особенно, что представляет отдельный интерес, с уйгурами. Уж не след ли это древних миграций индоевропейцев, например, тохаров, на восток?) выражена сильнее, чем у оленеостровца. Но модель считает, что это взято в основном от него, отсюда и заблуждение. Впрочем, и сами авторы пишут, что более адекватным видится вариант «третья группа, повлиявшая как на ямников, так и на современных армян».
Кроме уже перечисленных, явственно более сильную связь с ямниками проявляет выборка из Йемена (возникла мысль, что мы видим влияние небезызвестных Basal Eurasians — предположительно, именно йеменцы наиболее близки к ним из современных народов) и северо-западные европейцы. Это хорошо укладывается в предложенную авторами статьи модель, согласно которой северные европейцы в очень заметной мере являются потомками связанной с «ямниками» группы, которая мигрировала с востока и по большей части заместила предшествующее население. Кстати, у немцев (и германских народов в целом) необычно сильно проявляется все тот же компонент Gedrosia, которого не было у мезолитических охотников и неолитических земледельцев Западной Европы. И действительно, у восточногерманских образцов, принадлежащих к культуре шнуровой керамики, этот компонент появляется.
Карта для представителей КШК:

Очень похоже на «ямную» карту, не так ли? Но должны существовать и различия, попробуем их увидеть на разностной карте «самарцы» (красное) минус «шнуровики» (зеленое):

Картинка отнюдь не настолько контрастна, как было в случае сравнения ямников с оленеостровцем. Видимо, это связано с тем, что разница между сравниваемыми выборками в данном случае слабее. И все же некоторые взаимосвязи проявляются. Во-первых, заметно сильнее связь со шнуровиками у жителей острова Сардиния — как считается, они наиболее хорошо сохранили генофонд неолитических земледельцев Европы. Кроме этого, лучше связаны со шнуровиками, чем с ямниками, люди из района Белоруссия-Польша-Западная Украина. И наоборот, «ямные» пятна выделяются вокруг Удмуртии (уж не там ли живут потомки «самарцев»?), в районе «Средняя Азия-Индия» (включая уже упоминавшихся выше уйгуров), и в Закавказье/Малой Азии. Можно предположить, что шнуровики получились в результате смешения неолитических земледельцев и группы, родственной «самарцам», но более западной, сильнее связанной с «белорусским» пятном (и слабее — с тремя «ямными»).
Намного более наглядна разностная карта представителей культуры линейно-ленточной керамики (неолитических земледельцев) и шнуровиков:

Два мира — красным выделены народы, в большей степени связанные с неолитическими земледельцами (в отличие от предыдущей карты, сардинцы здесь сильнее связаны с противоположной шнуровикам стороной), зеленым — связанные с заместившими и поглотившими их пришельцами, носителями компонентов WHG и ANE. Обратите внимание, что армяне здесь ярко-красные — это еще раз доказывает ошибочность модели «ямников» как смеси EHG и армян в пропорции 50/50. Ведь тогда «армянский» вклад у «шнуровиков» был бы заметно сильнее.
А вот разница с «оленеостровцем»:

Здесь мало что можно добавить к тому, что уже писалось про разницу «оленеостровец»-«самарцы». Разве что Западное Средиземноморье стало более зеленым, а Средняя Азия-менее.
Наконец, для полного комплекта добавлю карту сравнения с представителем более западного варианта охотников-собирателей, Loschbour:

Родство с WHG преобладает лишь в дальнем северо-восточном углу Европы. Таков печальный итог нескольких волн миграций с замещением предыдущего населения.
Результаты для представительницы культуры колоколовидных кубков очень близки предшествующей «шнуровой» выборке. Поэтому разностная карта между ними еще более невразумительная, чем при сравнении шнуровиков и самарцев. Дело усугубляется еще и тем, что образец ККК лишь один, а значит, случайные отклонения и прочий «шум» выше.
ККК минус КШК:

Судя по всему, у шнуровиков неколько выше доля вклада «охотников-собирателей» и «ямного» компонента в целом. В то же время «средиземноморский» компонент выглядит чуть сильнее у ККК. Но все это тонет в шуме.
Не вижу смысла приводить сравнения представительницы ККК с окружающими, аналогичные КШК, поскольку они выглядят практически так же. А следовательно, мой обзор закончен. Что ж, можно с глубоким удовлетворением отметить, что палеогеномы из работы Haak et al действительно проливают свет на процессы, происходившие в Европе на рубеже каменного и бронзового веков — естественно, уточняя и дополняя уже известное специалистам.

 и женского (розовые стрелки) населения в составе неолитической и степной миграций.")


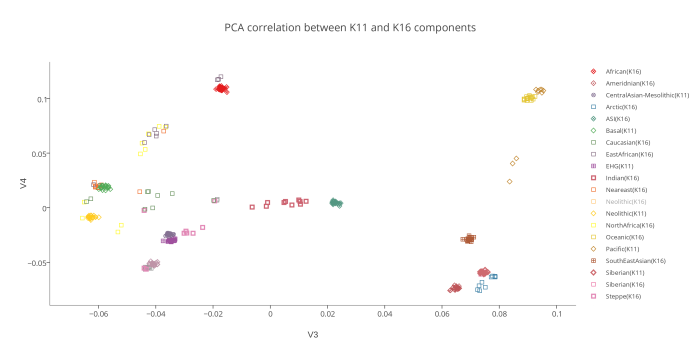 Вот эта таблица с усредненными значениями «симулянтов» компонентов K16 в калькуляторе K11 (колонки — компоненты K16, столбцы — компоненты K11, их пересечения — проекция компонентов K16 в компоненты K11).
Вот эта таблица с усредненными значениями «симулянтов» компонентов K16 в калькуляторе K11 (колонки — компоненты K16, столбцы — компоненты K11, их пересечения — проекция компонентов K16 в компоненты K11).





























Для отправки комментария необходимо войти на сайт.