Перед тем, как закрыть тему SPA, я решил поразмышлять о причинах неточности определения географического ареала происхождения с помощью генома. Те, кто воспользовался моей моделью для программы SPA (последняя версия — сентябрь 2016 года), могли убедится в том, что даже при наличии большого количества маркеров, модель не во всех случаях точно определяет ареал происхождения (даже с поправкой на погрешность радиусом в 500 км).
В основу алгоритма SPA положены примерно те же самые предпосылки, что и в случае с классическим анализом главных компонент (PCA)
- Первая предпосылка подхода SPA состоит в том, что частота аллели каждого SNP в популяции может быть смоделирована в виде непрерывной двумерной функции на карте. Другими словами, при выборе хромосомы индивидуума из локации с позицией (х, у) на карте, вероятность наблюдения минорного аллеля в SNP j на хромосоме может быть сформулирована в виде функции F (х, у), где Fj является непрерывной функцией, описывающей поведение частоты аллеля в зависимости от географического положения
- Затем на основании сказанного делается упрощающее предположение, что эта функция является экземпляром логистической функции
где х представляет собой вектор переменных, указывающих географическое местоположение и а и Ь коэффициенты функции. Авторы понимают каждую из этих функций, как функцию FJ функции наклона градиента частота в SNP J. Эта функция кодирует крутизну склона по норме а, при этом предпологается что смещение параметра b фиксировано. Кроме того, направленность наклона кодируется в значении вектора а. Более подробно, θj = арктангенс (aj(1) / aj(2)) могут быть приняты в знчения угла для SNP j, где aj(1) и aj(2) являются первым и вторым элементами вектора а.
Поскольку SPA имеет явные географические координаты, подход может быть расширен для систем за пределами обычной картезианской двумерной плоскости координат. В качестве демонстрации этого, авторы программы SPA использовали алгоритм для анализа пространственной структуры населения земного шара, в которой двухмерное отображение на двухмерной плоскости не может точно фиксировать структуру популяции. Таким образом, каждый индивид проецируется на точку земного шара в трехмерном пространстве. Соответственно, авторы использовали трехмерный вектор х (с ограничением || х || равным определенной константе), чтобы представить индивидуальную позицию.
Используя данные (генотипы индивидов из различных популяций из HGDP), авторы обнаружили что пространственная топология расположения индивидов в пространстве SPA мы наблюдали, что сильно напоминала топологию географической карту мира. В частности, люди из того же континента были сгруппированы вместе, а континенты были разделены примерно так, как это следовало бы ожидать из пространственного расположения.
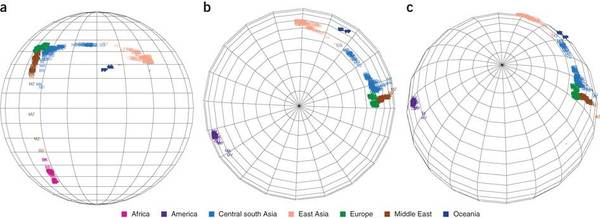
Главная проблема метода состояла в другом. Несмотря на точность топологии взаимного расположения индивидов, на карте SPA сильно искажены расстояния между континентами.
Например, продольный размер континента Евразии составил 92 градусов в SPA-пространстве земного шара, в то время как в пространстве реального земного шара — 150 градусов. Продольное расстояние между Европой и Северной Америкой составило 167 градусов на SPA карте земного шара, в то время как на самом деле оно составляет 90 градусов. Любопытно отметить, что мой опыт работы с этой программы показал, что наибольшую проблему составляют географические координаты долготы, в то время как широты предсказываются довольно точно. То есть по какой-то причине (несимметричность генетических градиентов в направлении север-юг и направлении восток-запад?) пространство SPA очень сильно искажается в продольном измерении (т.е в долготу).
По этой причине, вычисленные географические точки происхождения для европейцев часто оказываются в Атлантическом океана и так далее.
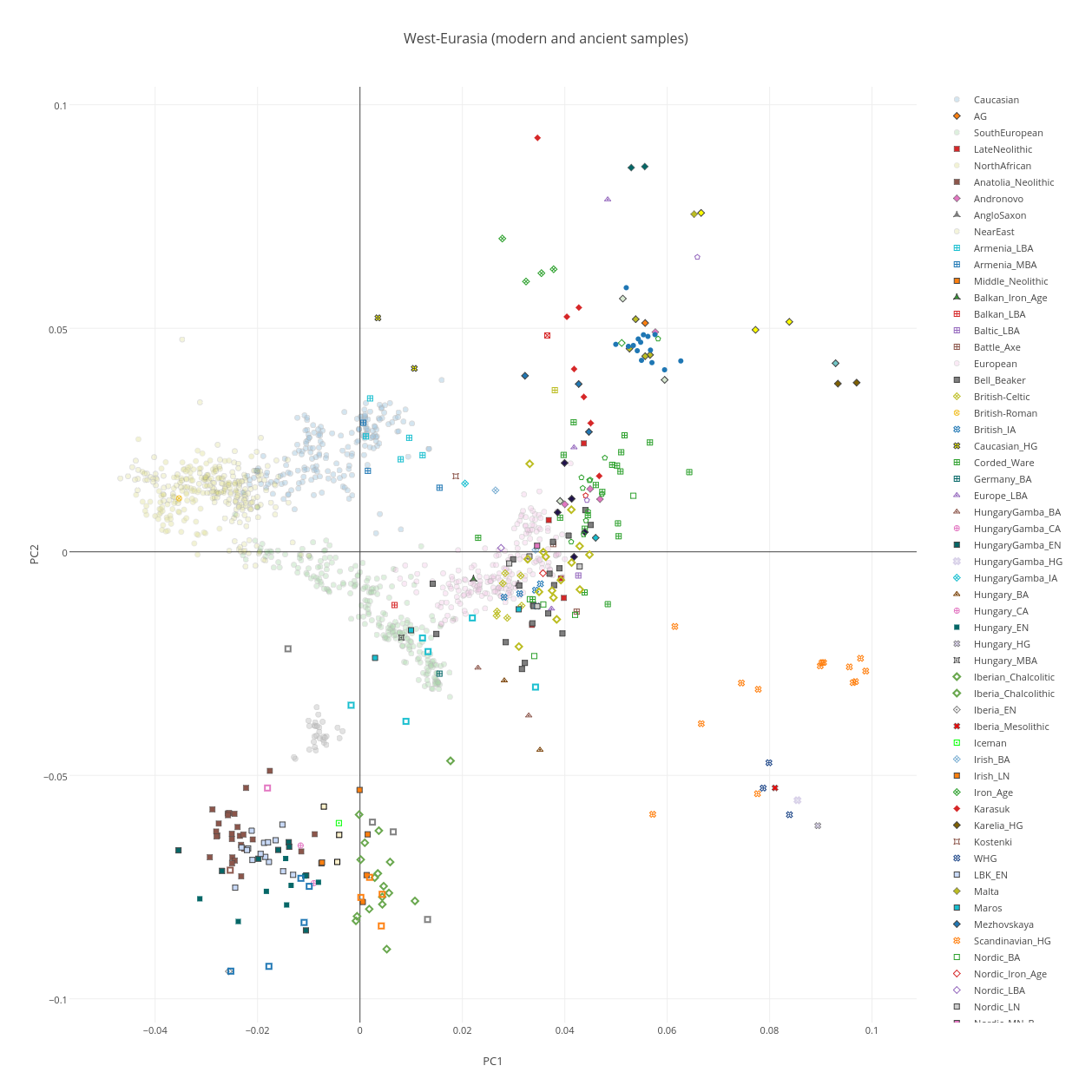
Я решил использовать данные импутированных генотипов для европейских популяций (я занимался их импутацией на протяжении последнего полгода). На этот раз я ограничился только европейскими популяциями. Я сделал два разных набора с разным числом снипов — один с 1 062 376 снипами, которые содержатся в платформах генотиприрования клиентов 23andme и FTDNA, другой — примерно 590 395 снипов. Обе модели можно скачать с Google Drive (здесь и здесь).
Несмотря на тщательный подбор снипов, обе модели продолжают страдать характерным сдвигом географических долгот, а это означает, что данная проблема обусловлена не выборкой генотипов, а самим алгоритмом программы (т.е. улучшение качества выборки или увеличение количества снипов не приводит к повышению точности даже в том случае, если мы используем для тренировки программы на обучающей выборке индивидов с известной географической локацией).
Это хорошо видно на полученных в ходе анализа моих собственных данных географических координатах 2 точек происхождения (одна из них в Гренландии, другая в Средиземном море)

Разумеется, вряд ли можно говорить о точности подобных вычислений. В ходе размышлений над способом решения проблемы я вспомнил о существовании ортогонального прокрустового анализа.

Я взял две матрицы — одну с географическими координатами (фактически центроиды — географические центры стран) и вторую с предсказанными (в модели 1M cнипов) величинами географических координат тех же самых образцов (с усредненными значениями по этносам), а затем совершил прокрустово преобразование в программе R, получив новую матрицу с преобразованными значениями координат. Ниже виден результат операции (преобразованные усредненные координаты образцов спроецированы вместе с центроидами на карту Европы). И хотя координаты по-прежнему немного сдвинуты относительно истинных, в целом результат уже гораздо лучше (правдоподобнее). При проведении прокрустова анализа, кроме Xnew (трансформированной матрицы), мы получили значения матрицы вращения R, s- коэффициент масштабирования и tt — вектор трансляции координат, минимизирующие дистанцию между матрицей предсказанных координат и матрицей географических координат.
При проведении прокрустова анализа, кроме Xnew (трансформированной матрицы), мы получили значения матрицы вращения R, s- коэффициент масштабирования и tt — вектор трансляции координат, минимизирующие дистанцию между матрицей предсказанных координат и матрицей географических координат.
Эти значения можно использовать для коррекции значений географических координат, рассчитанных в SPA. Я снова использую свои данные (2 предсказанные точки географического происхождения Xp):
Xt=sRXp + 1tt
При подстановке Xp получаем следующие значения
точка A: 60.245448+-11.059673 северной широты; 21.394898 +- -5.979712 восточной долготы (северо-западная Балтика и Скандинавия)
точка B: 43.000748+-8.801889 северной широты; 20.725216+-52.159598 восточной долготы (юго-восточная Европа, Балканы и Греция).


















Для отправки комментария необходимо войти на сайт.