Исследование генетики татар Поволжья при помощи анализа на IBD-сегменты
Не секрет, что под этнонимом «татары» в России зачастую скрываются совершенно разные этнические группы. Существуют татары казанские, астраханские, сибирские, крымские и т.д. В данном исследовании нас интересуют татары среднего Поволжья — казанцы и мишари.
Это достаточно многочисленный и активно тестирующийся народ, неплохо представленный в аутосомных базах 23andMe и FTDNA. По мере роста статистики прогонов татарских генотипов через калькулятор Вадима Веренича К27, я начал впадать в некоторое замешательство. В своем большинстве татары получались довольно близкими друг к другу по соотношению предковых компонентов Admixture. Однако одновременно существовали и различия, где было весьма сложно понять — не результат ли это попросту случайных отклонений? Разделение между казанскими татарами и мишарями проявлялось скорее как тенденция к несколько большим значениям «балто-славянских» и «финских» компонентов у вторых, чем как явный сигнал.
Поэтому при появлении у меня нового инструмента — скрипта, анализирующего наличие общих IBD-сегментов с научными выборками, я не замедлил пропустить через него имеющиеся генотипы татар из коммерческих выборок. Сразу же проявились различия, что позволило сделать вывод — несмотря на сходство татар по пропорциям предковых компонентов, их источники частично различаются.
Чтобы по возможности снизить влияние случайных отклонений, я постарался выделить усреднения по территориально-этническим группам. Наиболее бросающимся в глаза признаком казанских татар оказалось большое количество общих сегментов с марийской и чувашской выборками. Однако это еще не означает, что казанцы разделяют большую часть общих предков с марийцами или чувашами. Дело в том, что эти выборки испытали очень сильный генный дрейф. В результате даже не очень значительное родство с ними проявляется весьма ярко. В прошлой заметке я назвал это «эффект ашкенази», по имени наиболее известного примера. Судя по всему, марийцы и чуваши разделяют заметную часть общих предков, поэтому и «эффект ашкенази» у них общий.
Усреднение по трем казанским татарам из Апастовского района Татарстана:
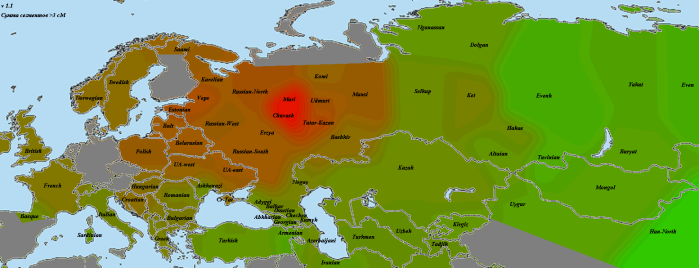
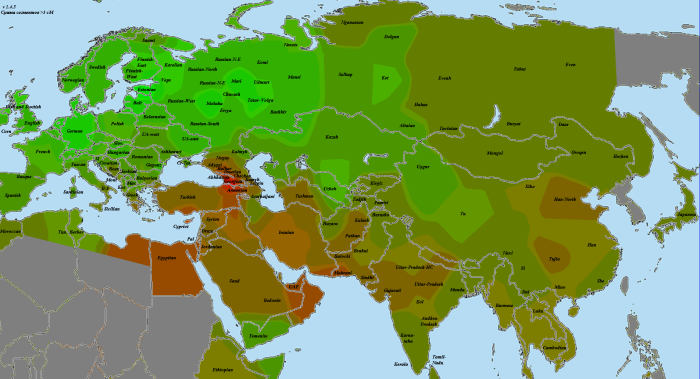
Довольно типичная картина — фоновая засветка по Восточной Европе, яркое пятно у марийцев и чувашей и более бледное — у татарской научной выборки. Точный источник татарской выборки мне неизвестен, но сравнительно слабые показатели могут хорошо объясняться большей численностью и генетическим разнообразием татар.
Татары из Тархановского района, 5 человек, выглядят весьма похоже, лишь марийско-чувашское пятно менее яркое:
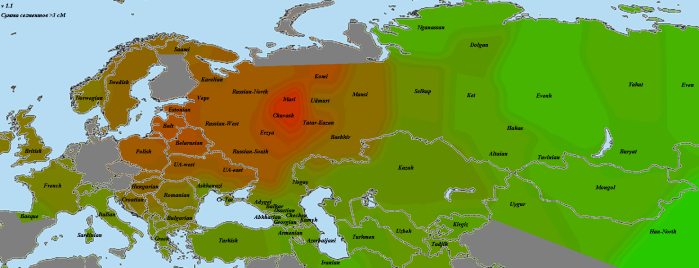
Татары из северо-западной части Башкирии, четыре человека. По сравнению с предыдущими выборками, добавилось некоторое влияние удмуртов и башкир:

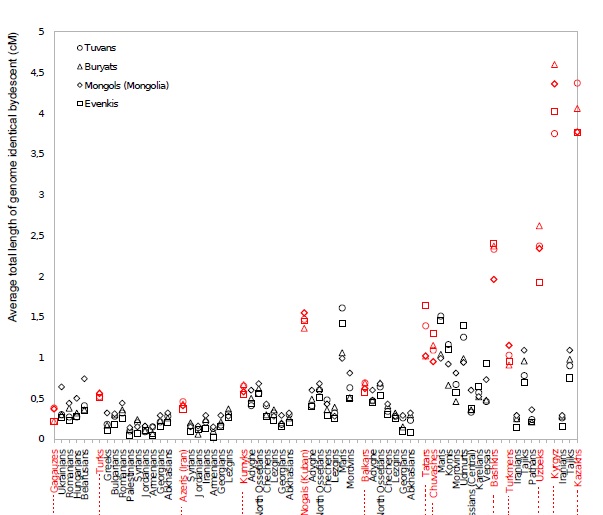
Насколько же велико может быть количество общих предков татар с чувашами и марийцами? Попробуем сравнить апастовскую выборку с усреднением по трем чувашам:
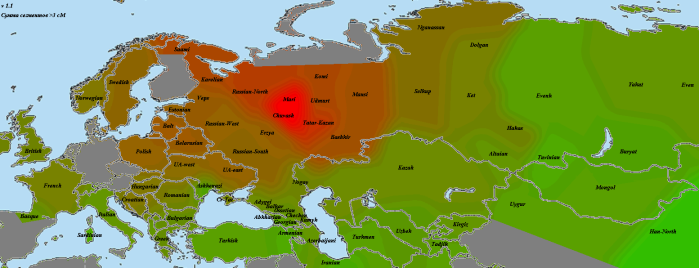
В калькуляторах на базе Admixture у чувашей ярко проявляется «уральский» компонент, и здесь мы хорошо видим его распространение — от саами до манси. Уровень пересечения с чувашской выборкой при моих типичных настройках — 115 сМ. Примерно такой же уровень получился у марийца (отличие от чувашей — в более высоком пересечении с марийской выборкой). При этом у людей с наполовину марийским или чувашским происхождением этот показатель составил чуть меньше 80. У апастовской выборки — 67. Можно сделать прикидку, что при недавнем адмиксе это соответствовало бы примерно 1/3 общих предков. Однако если эти предки жили давно, когда дрейф проявился еще не так сильно, их доля могла быть выше. Таким образом, оценкой снизу будет 30%. Провести оценку сверху поможет упоминавшийся «уральский» компонент. При калибровке К27 его содержание у чувашей получилось равным 19, усреднение по татарам из апастовской выборки — около 9. Таким образом, даже если все не пересекающиеся с чувашами предки были из популяций с нулевым содержанием этого компонента (что малореально), вклад чувашей не мог быть выше 50%. Думаю, что наиболее реалистичным вариантом будет все же 1/3.
Разумеется, существует еще вариант, что чуваши получили «уральский» компонент уже после разделения с татарами. Тогда количество общих предков может быть и гораздо большим. Однако этому варианту скорее соответствует некий более древний уровень родства, чем рассматриваемые здесь исторические времена.
Я попробовал подсчитать, исходя из предположения, что «чувашские» компоненты составили 1/3 наследственности татар, на что могли быть похожи оставшиеся 2/3 по К27. В одиночном режиме результат оказался непохожим ни на один народ, кроме самих татар. В режиме смеси комбинации тоже показались на первый взгляд очень странными, однако, как мы позже увидим, кое-какой смысл в них был:
Using 2 populations approximation:
1 Nogay_D+Russian_Novgorod_D @ 6,174824
Using 3 populations approximation:
1 50% Russian_North_R8 +25% Kazakh_R2 +25% Romanian_D @ 3,826868
2 50% Russian_North_R8 +25% Bulgarian_S14 +25% Kazakh_R2 @ 4,087314
У меня не нашлось полноценной мишарской выборки из районов за пределами Татарстана и Башкирии, поэтому пришлось объединить три образца, получившиеся похожими и по IBD-картографу, и по предковым компонентам в калькуляторе Вадима Веренича. Первый происходит из мишарей Нижегородской области, второй — из пензенских мишарей, третий — из служилых татар Самарской области.
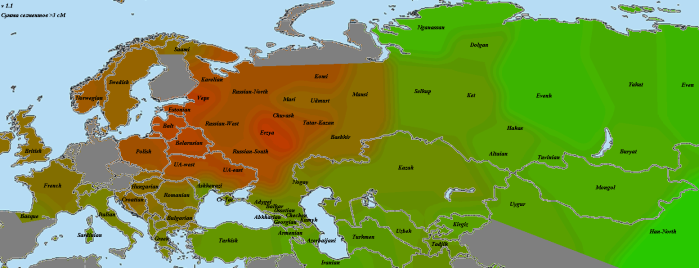
Как мы можем видеть, здесь не только нет «марийского» пятна, но даже наоборот — на этом месте показано уменьшение количества общих сегментов по сравнению с соседними популяциями. Родство с чувашами имеется, однако, очевидно, идет по другой линии предков чувашей, не совпадающей с предками марийцев. Наиболее же сильно выделяются эрзяне. Как и в случае родства казанских татар с чувашами, это вовсе не говорит об определяющем вкладе эрзян в генетику мишарей. Нижний предел я бы оценил аналогичным предыдущему случаю методом примерно в 20-25%. Что касается верхнего ограничителя, тут сложнее из-за отсутствия специфического «эрзянского» компонента Admixture. Если ориентироваться на общий восточноевропейский компонент Balto-Slavic, то он ограничивает максимальный уровень примерно 70-80 процентами. Вполне возможно, что предками мишарей были не сами эрзяне или мокшане, а родственная им соседняя популяция — это дополнительно затрудняет оценку.
Для сравнения, эрзянская выборка, пять человек:

Мишари из Дрожжановского района Татарстана, три человека:
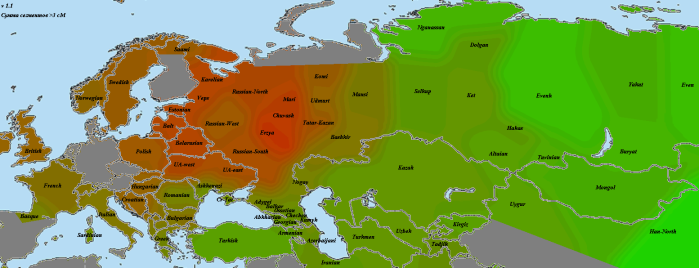
Картина схожа с предыдущей мишарской выборкой, однако у марийцев уже нет провала. Возможно, это связано с близостью к Чувашии, возможно — с влиянием казанских татар.
Выборка мишарей из Башкирии получилась ближе к казанскому варианту. Это может объясняться спецификой именно данной выборки, либо различиями между мишарями в целом. Придумать объяснений можно много, но думаю, здесь нет смысла в них вдаваться.

Итак, для каждого из народов (или, при другом подходе, субэтносов), мы видим на картах один из предковых источников. Однако попытка вывести оставшиеся источники методом пересчета предковых компонентов оказалась малоудачной. Чтобы решить эту проблему, я попробовал визуализировать разницу с первым источником. На карте приведена разница между первой («сборной») мишарской выборкой и эрзянами, для контрастности умноженная на три:
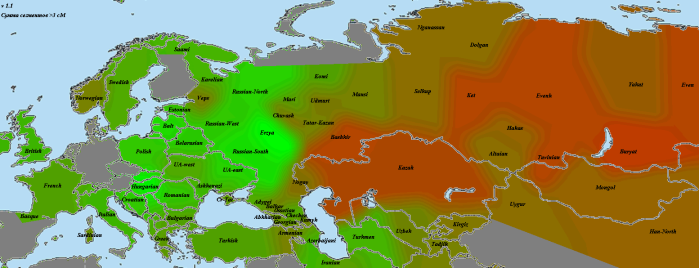
Зеленые тона показывают выборки, более близкие эрзянам, красно-бурые — мишарской выборке. Промежуточные варианты одинаково близки и тем, и другим. Максимум разницы в пользу мишарей достигается из крупных выборок у бурят и тувинцев, что очень хорошо совпадает с недавней работой по генетическим следам тюркской экспансии . Немногим отстают от них и башкиры с казахами. Интересно, что кавказские выборки, за исключением ногайцев и балкарцев (наличие в этой компании армян остается загадкой )) ), получились несколько ближе к эрзянам, что говорит против теории о связи мишарей с Кавказом (либо она каким-то образом идет через эрзяноподобную сторону). Пятно у вепсов, думаю, тоже что-то означает, поскольку в слабом виде видно у многих татар. Однако это может быть и следствием более высокого уровня дрейфа у вепсов по сравнению с соседями.
При построении аналогичной карты для пары казанцы/чуваши в качестве базовой выборки я выбрал апастовскую. Башкирские по понятным причинам не могут служить типичным образцом, а тархановская демонстрирует тенденцию сдвига к мишарям. К тому же наиболее родственная чувашам выборка может выявить отличия с ними более показательно.

Зеленая зона вдоль северной части Сибири объясняется более высоким уровнем родства с этими народами у чувашей, чем у татар (все тот же уральский компонент). Родство с народами степной полосы и возможной тюркской прародины находится на примерно одном уровне у «чувашской» и «нечувашской» части генома казанских татар. Родство же с выборками Средней Азии, Кавказа, Средиземноморья — выше. Вероятно, средиземноморскими же пересечениями объясняется повышенный уровень общих сегментов с ашкенази (не забываем, что это число надо делить в разы из-за ашкенази-эффекта). Примерно такого же уровня пятно с крымскими татарами выглядит бледнее из-за небольшой площади полуострова. Интересно также пересечение с болгарами. Не думал, что их тюркский компонент проявится настолько заметно. Впрочем, возможно, это объясняется турецкими или татарскими вливаниями, а не древними булгарами. Ну и обращает на себя внимание знакомое пятно у вепсов и эстонцев.
А теперь вспомним еще раз раскладку при попытке реконструкции «нечувашской» части на базе К27:
2 50% Russian_North_R8 +25% Bulgarian_S14 +25% Kazakh_R2 @ 4,087314
Неправильно, однако уже не так странно, как казалось вначале.
Не следует думать, что перечисленные популяции составляют 2/3 наследственности казанских татар (раз уж 1/3 мы оцениваем вклад «чувашской» стороны). Более вероятным кажется вариант, когда заметную часть от этих 2/3 занимает некая нейтральная по отношению к чувашам популяция, у которой уровень IBD сегментов с другими уральцами и восточноевропейцами был близок к ней. Из-за нейтральности она плохо выделяется на картах IBD-разности, однако калькуляторы на базе Admixture показывают — вклад пришельцев с далекого Юга или Востока не мог быть определяющим. Возможно, именно на эту популяцию намекают «вепсско-эстонское» и «южно-русское» пятна.
В завершение я хочу привести карту разницы между мишарями и казанцами:
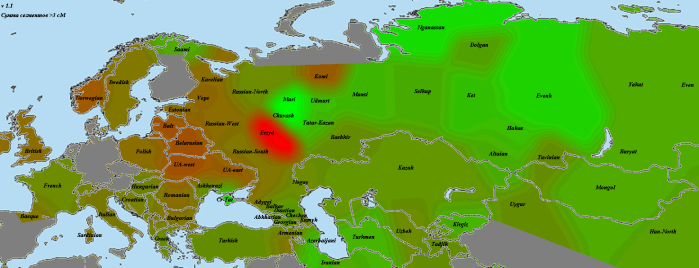
С казанской стороны мы видим знакомые марийско-чувашское и крымско-татарское пятна, а также, слегка неожиданно, но не удивительно, азербайджанское (с расширением вдоль Южного Каспия). С мишарской стороны знакомые эрзяне, неожиданно выделилась территория ВКЛ (какие-то вливания оттуда в геном мишарей?), и, по совсем непонятной причине, выборка коми. Родство с азиатскими выборками идет с некоторым перевесом в пользу казанцев, особенно в «зоне марийско-чувашского влияния».
Аналогично примечанию к предыдущей карте, не следует забывать — здесь показана разница. Нейтральная общность может быть велика, но не видна этим методом.

 и женского (розовые стрелки) населения в составе неолитической и степной миграций.")



























{kind=link}
Для отправки комментария необходимо войти на сайт.