Мой блог посвящен преимущественно тематике аутосомной ДНК, однако время от времени я затрагиваю тему однородительских маркеров происхождения (Y-ДНК и митоДНК). Начну заметку издалека.
Среди обывателей села Стахова бытует легенда, о том, что род Вереничей пришли на земли пинского Полесья из Югославии.К сожалению, как и в большинстве подобных легенд, cовершено невозможно разобраться в том, где правда, а где позднейшие выдумки. Так и в этом случае. Ни в одном из имеющихся e меня исторических документах нет даже и намека на балканское происхождение Вереничей. Даже в самых ранних документах (например, в «Ревизии пущ и переходов звериных в бывшем Великом княжестве Литовском с присовокуплением грамот и привилегий на входы в пущи и на земли, составленной старостою мстибоговским Григорием Богдановичем Воловичем в 1559 г. «, или в «Писцовой книге Пинского староства Лаврина Воина, 1561—66«) уже видно, что даже в то время род Вереничей на Полесье считался «издавним«.
Так в ревизии Воловича (1559 года) читаем, что
«Павел Веренич на дворище у Стохови жъ не покладалъ листовъ, только давность, и на другое дворище у Дубой».
Слово давность означает существование в течение долгого времени, издревле, искони. Происходящие от корня этого слова прилагательные и наречия попадаются в разных актах с конца XIII века. Как юридический термин существительное <давность> употреблялось уже весьма рано в западнорусском законодательстве; собственно же в России оно появляется в виде термина лишь с XVIII века. Выражение земская давность было юридическим термином в Литовском Статуте, из которого заимствовано русским законодательство.
В строго юридическом смысле срок давности владения определялся десятью годами. Впрочем, здесь давность может употребляться в другом значении. Так, в актовых материалах все той же «Ревизии пущ и переходов звериных в бывшем Великом княжестве Литовском с присовокуплением грамот и привилеев на входы в пущи и на земли, составленная старостою мстибогским Григорием Богдановичем Воловичем» в числе прочих землевладельцев Пинского повета упомянуты Грынь Веренич с братом Павлом «с имений своих стародавних [т.е. с незапамятных времен] военную службу служащих«. Судя по этому, Вереничи могли появится в Стахове уже в середине 15 века, если не раньше.
Когда, откуда, и при каких обстоятельствах — обо всем этом известные мне историко-юридические источники умалчивают. Более поздние документы не только не дают ответа на эти вопросы, а скорее еще больше запутывают ситуацию. Так например в «Выводе фамилии урожденных Стаховских придомка Веренич» (Год 1802 Месяца ноября двадцать второго дня на на сессии Депутации выводовой Губернии Минской) читаем следущее:
«Принесена была просьба от фамилии древней родовитой панской шляхты урождённых Вереничей Стаховских герба “Огончик” (пол-стрелы белой на половине перстня стоящей, в поле красном, над шлемом две женские руки вытянутые вверх) которая на наследственных землях и осадах в повете пинском лежащих от найяснейшых времён королевства Польского, прерогативами шляхетства пользовалась, и клейнотом родовитости неискаженно и непрерывно пользовались. [стр. 616] В потверждение указов найяснейшей воли – линия родословной своей вместе с документами перед депутацией выводовой губернии Минской составлена, потверждена доводами и внесена в дворянские книги Минской губернии в соответстии с законом.Родословие своего дома разделили на две линии. Дух родных братьев Семена и Дмитрия Вереничей Стаховских за родоначальников взяли, и от них до себя довели. И правдивость этого они через доказательства и документы следующим порядком довели. Семен и Дмитрий Вереничи Стаховские братья между собой родные. В повете Пинском осели и дали начало своему роду и фамилии. И в подтверждение своего первого поколения они предъявили привилегию от наияснейшего короля польского Сигизмунда Августа за год тысяча пятьсот шестьдесят шестой от июня двадцатого дня где, между другими для шляхты пинской пожалованиями за военную службу выше упомянутым Семену и Дмитрию Вереничам Стаховским земли в наследственное владение в повете Пинском лежащими дворища Веренича в Стахове и Дубой называющееся им и потомкам их пожаловал…»
Содержание начала текста весьма типично для подобных документов, но здесь нет сведений о точном времени появления Вереничей в Стахове, не говоря уже о явных хронологических несуразицах, которые я разбирал в другой заметке.
- Во-первых, под «привелем» 1566 года понимается общий «привилей» Сигизмунда-Августа, данные всей пинской шляхте в подтверждение их землевладельческих и шляхецких прав.
- Во-вторых, Семен и Дмитрий жили не в 1566 году, а как минимум на сто лет раньше — около 1456-1466 годов. В доказательство верности моих вычислений можно привести следующие аргументы. В решении судей Главного Трибунала ВКЛ от 1637 года упоминается о привелее кн. Марии Семеновны (+1501) ( в документе ошибочно указано Ярославовны) и ее сына кн. Василия Семеновича (+1495) от 6998 года индикта 8 (1490 года согласно современному летоисчислению), в котором подтверждается совместное владение Волошиным (sic!) Павлом и Ходором Вереничами даниной своей бабки в селе Тупчицы, Согласно родословной, Павел — сын Дмитрия и племянник Семена. В следующем по времени привилее кн. Федора Ивановича Ярославича от 26 апреля 1514 данном дочерям Антона (Андрей?) Дмитриевича Веренича потдверждается их вотчинное права на земли пожалованные их отцу в Стахове, Дубое и Тупчицах. Очевидно, Антон(или Андрей) — тоже сын Дмитрия, и более того, в 1514 году его дочери были уже совершеннолетними.
- В-третьих, в переписе войска литовского 1528 года упомянут пинский боярин Верениш (sic!), который служил «сам со своего имения». Далее, из судебного дела от 26 марта 1543 года по иску Пашки Павлова и его братьи Игнатия и Гаврила к Ваське Лозичу, который унаследовал по своей жене Ульяне Лукашевичевой Веренич часть имений Дубой и Стахово. мы узнаем, что в 1543 году внуки Дмитрия (Пашко Павлович и его двоюродные братья Гавриил и Игнат Васильевич) были уже взрослыми, так же как и покойная Ульяна Лукьяновна (дочь Лукьяна Семеновича, внучка Семена Веренича), после смерти которой третья часть дворища Веренич в Дубое и дворища Веренич в Стахово перешла к Ваське Лозичу.
Далее, в 1554 году — за 12 лет до указанной в привелее даты — в материалах, собранных в ходе ревизии пущ и переходов лесных -упомянуются Грынь Веренич с (троюродным) братом Павлом с имений своих стародавных военную службу служащих. Как известно, Грынь — внук Семена, а Павел или Пашко — внук Дмитрия. О самих Семене и Дмитрии ни слова, хотя если бы они жили в это время, то скорее всего именно они или их сыновья были бы записаны как старшие в своем роду, но никак не их внуки.В 1559 году, по все той же ревизии Воловича, в числе земян Стаховских опять упоминается Павел Веренич, правда, уже без Гриня. В тексте четко сказано, что Павел не покладал листов (т.е. не предъявил привелея), только давность на дворище у Стахова и другое дворище у Дубоя. Поскольку большую часть книги Воловича составляют привелеи, выданные или подтвержденные королевой Боной, следовательно, от Боны Вереничи привлеев не получали, по крайней мере, на земли в Дубое и Стахове.Все вышесказанное означает, что уже задолго до 1566 года Вереничи владели своими дворищами и землями на основании вотчинного права, и что феодальные права Вереничей на эти земли восходят — как минимум -временам кн. Марии Семеновны и ее сына Василия (то есть к периду между 1475-1490 гг).
Реконструкция позволяет очертить интервал появления Вереничей в Стахове — но с обстоятельствами появления по-прежнему нет никакой ясности. Поскольку скудные исторические свидетельства обходят этот вопрос сторонй, то можно обратиться к преданиями. Среди старожилов села Стахова якобы сохранилось следующее якобы древнее предание:
Когда-то, давным-давно, жил на Полесье князь Карачинский (sic!). В его владениях находился большой дремучий бор, около которого проходил торговый шлях. По прошествии времени, в этом бору поселилось 100 половцев, которые совершали нападения на проезжающих купцов и селян. Князь, прослышав о разбойниках, повелел своим «палявничим» (охотникам) узнать, где находится разбойничье логово. Один из охотников решил проследить путь до логово половцев и стал делать топором зарубки на деревьях. Услышав стук топора, войны князя отправились в сторону, где раздавалось эхо стука топора. Таким образом, они вышли прямиком на логово разбойников и истребили их. В награду за верную службу, князь наградил находчивого охотника землям, где находился стан половцев. Охотник постоянно носил с собой «Ксендз Лаврентий Янович, каноник венденский, в своей речи на погребении Элжбеты с Стаховских Каренжины, жены вилькомирского судьи, изданной в сборнике «Золотой улов на реках и водах смертности сего мира и т.д» (Вильно 1665 г.) размещает следущее предание, относящиеся к истории Стахова.: «Князь Карачевский, владелец обширных волостей, лежащих на Пинщине, крайне скудными силами 100 половцев положил трупами и на там же месте похоронил, как и по ныне свидетельсвтуют о том курганы того места. За это мужесто правящий князь ему отдал в удел это поле, а также столько земли, сколько мог объять звонкий звук трубы. Отсель то земельное надание стало называтся Стоховым, потому что там похоронено сто убитых врагов.» (веренька, вярэнька), и поэтому его прозвали Веренькой. Его потомки приняли прозвище родоначальника в качестве фамилии.
К сожалению, изучение этого предания показывает его недавнее происхождение. Скорее всего, оно выписано из 9-го тома «Полного географического описания нашего отечества» изданного в 1905 году В.П.Семеновым-Тян-Шанским , куда, в свою очередь перекочевало из известного издания «Słownik geograficzny Królestwa Polskiego» изданного в 1880–1902 гг., а именно из 11 тома, в котором на стр.171-172 была размещена довольно объемная статья Александра Ельского и Эдварда Руликовского о Стахове. Именно с подачи Руликовского в этой статье была размещена выписка из издания 17 века:
«Ксендз Лаврентий Янович, каноник венденский, в своей речи на погребении Элжбеты с Стаховских Каренжины, жены вилькомирского судьи, изданной в сборнике «Золотой улов на реках и водах смертности сего мира и т.д» (Вильно 1665 г.) размещает следущее предание, относящиеся к истории Стахова: «Князь Карачевский, владелец обширных волостей, лежащих на Пинщине, крайне скудными силами 100 половцев положил трупами и на там же месте похоронил, как и по ныне свидетельствуют о том курганы того места. За это мужесто правящий князь ему отдал в удел это поле, а также столько земли, сколько мог объять звонкий звук трубы. Отсель то земельное надание стало называтся Стоховым, потому что там похоронено сто убитых врагов.»
В приведенном отрывке приводится родословное предание рода Стаховских герба Огоньчик, (проживавшего в мстиславском, виленском, новогрудском и пр. воеводствах ВКЛ), генеалогическая связь которого с Вереничами пока никак не проясняется. Главным фигурантом здесь выступает князь Карачевский (которого, видимо, Cтаховские считали своим предком), а вовсе не «охотник с сумкой из бересты». Можно с уверенностью сказать, что «легенда старожилов» Стахова появилась самое ранее в начале 20 века в среде «грамотеев» села Стахове как результат переосмысления текста статьи их энциклопедического справочника, а затем объединения легенды об основании Стахова с народной этимологии фамилии Веренич.
Итак, и этот источник не дал нам ничего ценного. Поскольку возможности документальной генеалогии на этом этапе практически исчерпываются (и открытие новых источников вряд ли предвидится), остается обратится к новой отрасли — ДНК-генеалогии.
Генетическая генеалогия использует ДНК-тесты совместно с традиционными генеалогическими методами исследования. Каждый человек несёт в себе своего рода «биологический документ», который не может быть утерян — это ДНК человека. Методы генетической генеалогии позволяют получить доступ к той части ДНК, которая передаётся неизменной от отца к сыну по прямой мужской линии — Y-хромосоме. ДНК-тест Y-хромосомы позволяет, например, двум мужчинам определить, разделяют ли они общего предка по мужской линии или нет. ДНК-тесты не просто помощь в генеалогических исследованиях — это современный передовой инструмент, который генеалоги могут использовать для того, чтобы установить или опровергнуть родственные связи между несколькими людьми.
Итак, в 2008 году узнал свою Y-хромосомную гаплогруппу (I2a). Немного терминологии для читателей, далеких от науки:
Гаплогруппа (в популяционной генетике человека — науке, изучающей генетическую историю человечества) — группа схожих гаплотипов, имеющих общего предка, у которого в обоих гаплотипах имела место одна и та же мутация — однонуклеотидный полиморфизм.
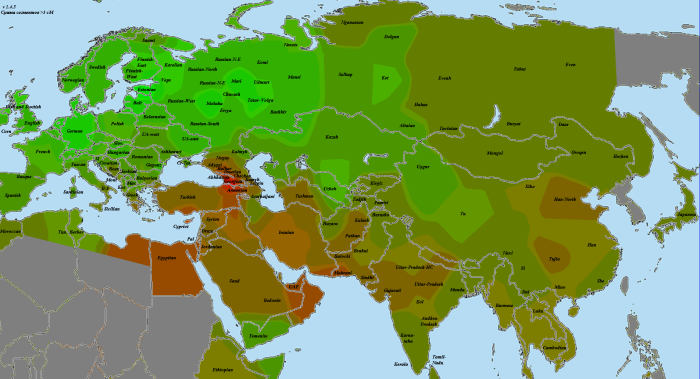
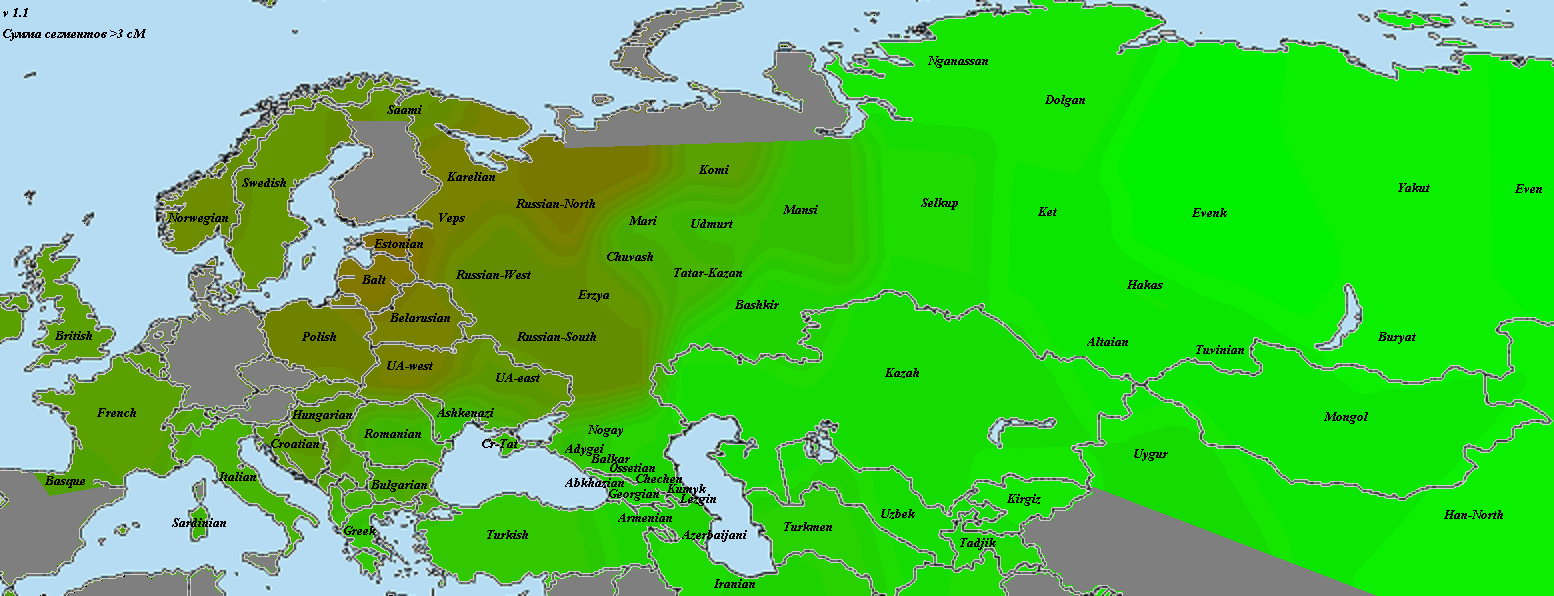
Позднее протестировались еще 2 Веренича, и наши гаплогруппы совпали, что подтверждается достоверность официальной родословной. Казалось бы, после всех усилий, можно было бы легко определить ареал, откуда появились предки Вереничей (очевидно, что это ареал с наибольшей частотой или наибольшим разнообразием гаплогруппы I2a). На поверку же все оказалось гораздо сложнее. Географический ареал гаплогруппы I2a (вернее ее восточноевропейской, «динарской» ветви) характеризуется бимодальным распределением — в восточной Европе они приходятся на регион Полесье-Карпаты и на регион Балкан (с макисмальной частотой в Боснии-Герцеговине).
По иронии cудьбы, именно с этими двумя регионами связаны две наиболее вероятные версии происхождения Вереничей. Таким образом, знание одной лишь корневой гаплогруппы мне, по большому счету, не помогло ни подтвердить, ни опровергнуть одну из этих альтернативных версий.
Тупиковая ситуация изменилась лишь после того, как один из Вереничей сделал полный сиквенс Y-хромосомы (BigY в FTDNA). Благодаря ему удалось достаточно точно позиционировать расположение нашей ветви-кластера внутри общей структуры филогенетического дерева I2a.Благодаря присутствию Y-хромосомного сиквенса (YF03602) представителя рода Вереничей в базе данных yfull.com (спасибо за помощь Vladimir Semargl и Vadim Urasin) представляется возможным оценить возраст моего кластера. На настоящий момент в него входит еще один полный сиквенс Y-хромосомы (YF04188), о хозяине которого мне ничего неизвестно.
Возраст линии Вереничей оценивается в 1438 лет до настоящего времени, линии YF04188 — всего лишь в 546 лет.По расчету снип-мутаций возраст I-Y17665 (и возможно I-A7318) оценивается примерно в 1000 лет (т.е. временами Киевской Руси), а возраст родительской ветви A1328 в 1850 лет до настоящего времени (начало нашей эры). Возраст, определенный по снипам, указывает на время выделения ветви I-A1328, хотя возраст последнего общего предка (определенный по значениям других маркеров Y-хромосомы) чуть ниже -1400 лет (т. е примерно 5-6 века нашей эры). То есть ветвь моих прямых предков в это время прошла пресловутое бутылочное горлышко, сопровождаемое, как правило, падением числа представителей линии и уменьшением разнообразия.
Здесь начинается самое интересное.
Недавно, зайдя на сайт проекта I2a в FTDNA, я обнаружил результаты некоего Враньешевич из Черногории. Я бы не обратил на него внимание, если бы он не попал в тот же кластер, что и я (в этот кластер входит ветвь Вереничей, гаплогруппа (I2-A7318, т.е подветвь I-A1328)).Я решил рассчитать возраст I-A1328 с помощью калькулятора semargl.me и стандартных для набора 37 маркеров скорости мутации. К сожалению, в базе данных Semargl немного гаплотипов из конкретно моего кластера и ближайщих к нему братских кластеров. В общем возраст, по ASD методу получилось что возраст моего кластераI (Y17665) — 1050 лет, а при подключении (в качестве outgroup) гаплотипа из I-A1328* возраст кластера I-A1328* составил примерно 1850 лет. То есть, это верхний интервал временного промежутка, когда мог жить последний мой общий предок (MRCA) и Враньешевича.
I2a2 ‘Dinaric’ ..L621>CTS10228>S17250>Y4882>A1328>A7318 (I-A7318)
568 362501 Verenich Werenicz,Werenich,Verenich,Werenitz,Stachowski. Belarus I-A7318
I2a2 ‘Dinaric’ ..L621>CTS10228>S17250>Y4882>A1328 (I-A1328)
564 E13120 Vranjesevic Vranjesevic Milan-Mico, birth 1913, death 1992 Bosnia and Herzegovina I-A1328
Нижний интервал можно определить с помощью калькулятора McDonald. Для вычисления дистанции в годах я сравнил значения 67-маркерного гаплотипа одного из Вереничей с аналогичными маркерами гаплотипа Враньешевича. 10 маркеров имеют другое значения. Получается разница в 10 маркеров на 67 маркерных гаплотипах.
Generations Probability Cumulative
1 0.000000 0.000
2 0.000000 0.000
3 0.000000 0.000
4 0.000004 0.000
5 0.000022 0.000
6 0.000091 0.000
7 0.000279 0.000
8 0.000699 0.001
9 0.001495 0.003
10 0.002825 0.005
11 0.004827 0.010
12 0.007592 0.018
13 0.011137 0.029
14 0.015396 0.044
15 0.020223 0.065
16 0.025408 0.090
17 0.030697 0.121
18 0.035824 0.157
19 0.040537 0.197
20 0.044616 0.242
21 0.047893 0.290
22 0.050258 0.340
23 0.051662 0.391
24 0.052111 0.444
25 0.051660 0.495
26 0.050401 0.546
27 0.048451 0.594
28 0.045943 0.640
29 0.043014 0.683
30 0.039796 0.723
31 0.036412 0.759
32 0.032973 0.792
33 0.029568 0.822
34 0.026274 0.848
35 0.023146 0.871
36 0.020225 0.891
37 0.017537 0.909
38 0.015097 0.924
39 0.012906 0.937
40 0.010961 0.948
41 0.009252 0.957
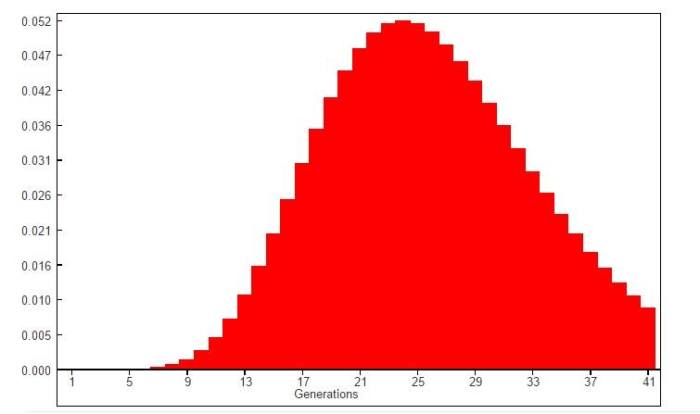

Пик гистограммы приходится на интервал между 21-30 поколениями, начиная с 26 поколения кумулятивная вероятность родства достигает убедительных значений достигая 0.95 в 41 поколении. Т.е. нижняя граница приходится примерно интервал в 600-1025 лет до настоящего времени — другими словами между 15 и 10 веками нашей эры.
Разумеется, c генеалогической точки зрения, исследование нижнего интервала (с общим предков в 14-15 веках нашей веры) более перспективен, тем более что я проследил свою прямую мужскую линию до 19 поколения.
Но насколько возможен факт наличия общего прямого мужского предка белоруса и черногорца в 21-30 поколениях? Дает ли генеалогия Вереничей предпосылки для такого утверждения? Прямых предпосылок, разумеется, нет.
Зато есть соображение ономастического характера. Один из сыновей второго родоночальника — Дмитра — Василь носил прозвище Волошин — так обычно в русских землях называли валахов, хотя часто прозвище Волошин не имело этнической коннотации и могло выступать в качестве отыменного прозвища: например, Володшин cын -> Волошин или Власий -> Волос -> Волошин. Наконец, составитель документа или переписчик мог сделать обычную описку. Впрочем, последнее опровергает существование 2 топонимов в окрестностях Стахова — урочища и острова Волошиново — причем именно там находились в 16-17 веках владения потомков Дмитра Веренича (старшим сыном которого являлся Василь Волошин). Кстати, любопытно отметить, что иногда в документах 16 века фамилия Веренич записывается не с окончанием —ч, а с более традиционным для южных славян окончанием — ш (Верениш)
А как же тогда быть с Вранешьевичем? Какое отношение он может иметь к валахам?
Лет 8 тому назад я порылся в исторических документах и обнаружил, что похожая фамилия Вранчич (в хорватском произношении Веранчич) действительно существовала на территории так называемого царства Сербия. После фактического распада Сербского царства (около 1366-1371 года), часть Вранчичей переселилось в Южную Сербию и Черногорию (где потомок Вранчичей воевода Радич Црноевич основал династию Црноевичей, которая в 15 веке праваила Зетой и Черногорией), другая перешла на службу к усилившемуся после падения «црства Српскаго» боснийскому королю Стефану Твртко I, который в 1370 и 1389 годах принял титул короля сербов, Боснии (1379) , Далмации и Хорватии (1389). Эти боснийские Вранчичи после падения Боснии (1463 год) под ударами турков частью переселились в Далмацию (г.Шибеник), которая с1420 была под венецианским владычеством, другая переселилась на границу Герцеговины и Черногории, где владели под турками «хематом» Вранеш, названого так в честь «валашского» князя Херака Вранеша (Вранеш — это герцеговинское диалектное видоизменение имени Вранчич).»Из возможных потомков Вранчичей, оставшихся в восточной Боснии и Герцеговине, особого внимания заслуживает «влашский» (sic!) кнез Херак (Владиславич?) Враньеш.
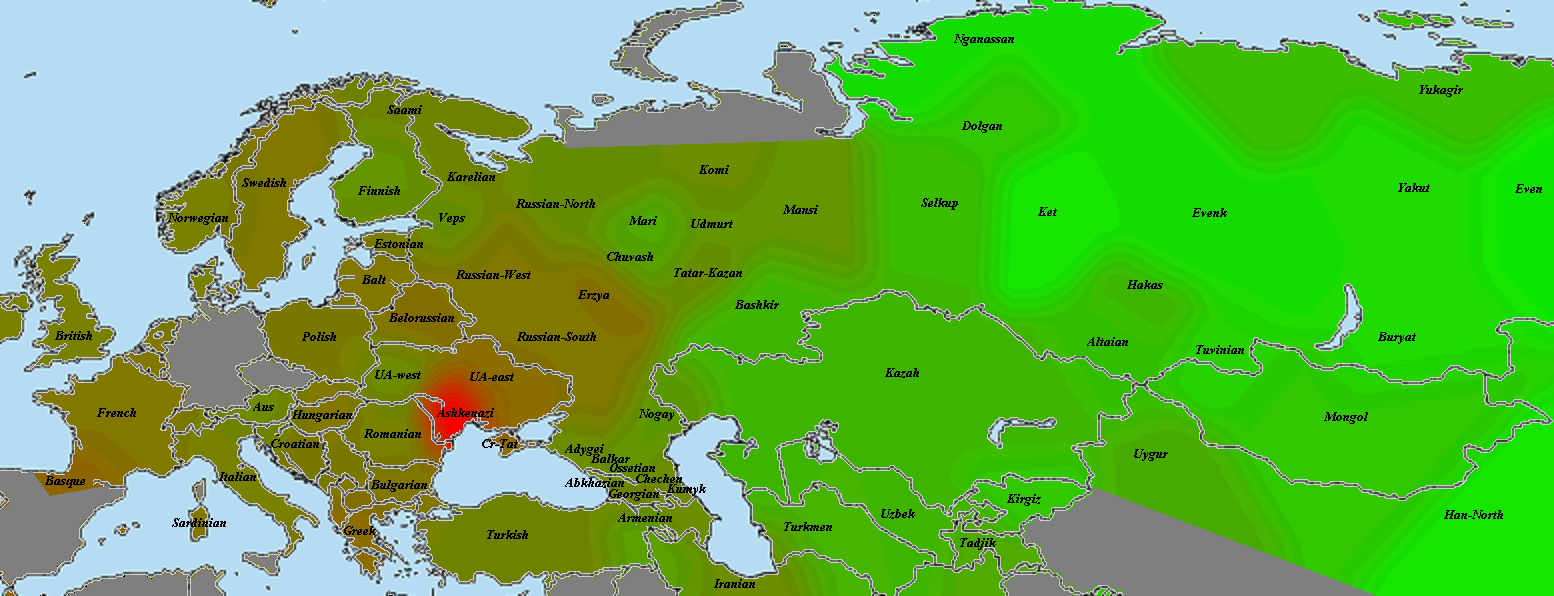
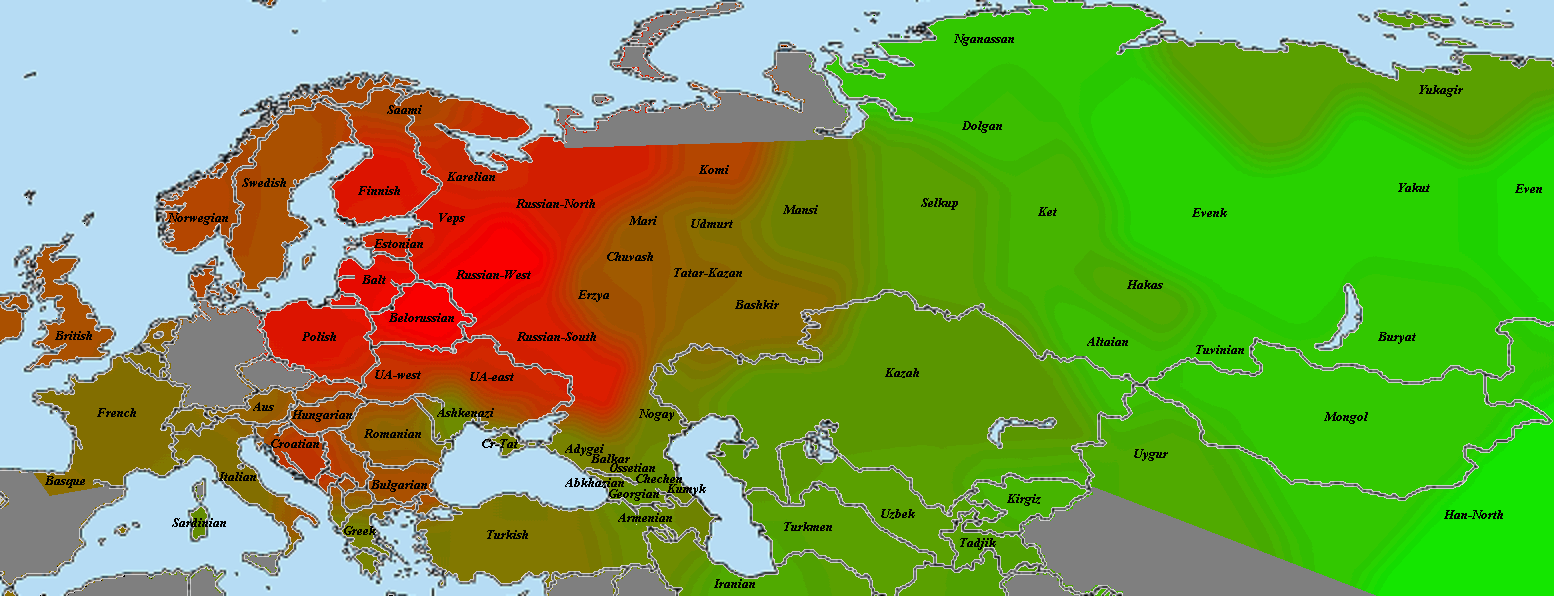
Казалось бы, вышеприведенные рассуждения выглядят убедительно. На самом же деле, остается главная проблема — дело в том, что фактически на протяжении 14-17 веков неизвестно никаких миграций жителей Балкан и влахов на территорию Полесья. Да, действительно была т.н. валашская колонизация, но она затрагивала главным образом территорию юго-западной Украины (прежде всего «червонной Руси» и «любельской земли», т.е. земли вокруг Львова, Звенигорода, Галича, Теребовля, Санока, Кросно, Белза, Замосця, Холма (Хелма). Причем интенсивность расселения «валахов» даже в этих регионах резко уменьшалось по мере продвижения на север (см. приложенную ниже карту).
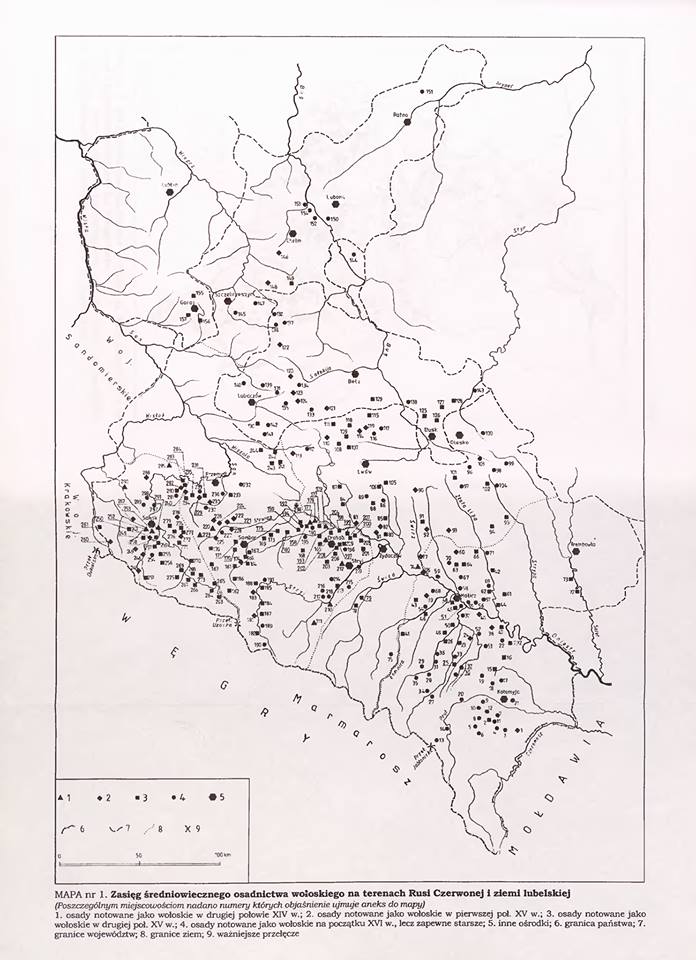
Например, на ближайшей к Полесью Волыни встречаются лишь фрагментарные упоминания бояр «Волошинов» в документах Метрики Литовской начала 16 века — они касаются пожалования земель в кременецком повете, т.е на рубеже ВКЛ и русского воеводства короны Польской (причем многие из этих «волошинов» носят чисто румынские имена Негое, Урсул и так далее). Такой же фрагментарный характер носят и земельные пожалования «волошинам» и на Подолье. И уж совсем единичные упоминания Волошинов мы находим в документах Метрики Литовской, касающихся земель современной Беларуси. Правда, на Брестчине одна семья «волошинов» — Ходько, Зань и Васько — получила в начале 16 века привелей на имение Чернско (от них происходит род Черских в брестском воеводстве, который вымер в 17 веке).

 и женского (розовые стрелки) населения в составе неолитической и степной миграций.")

 Вот эта таблица с усредненными значениями «симулянтов» компонентов K16 в калькуляторе K11 (колонки — компоненты K16, столбцы — компоненты K11, их пересечения — проекция компонентов K16 в компоненты K11).
Вот эта таблица с усредненными значениями «симулянтов» компонентов K16 в калькуляторе K11 (колонки — компоненты K16, столбцы — компоненты K11, их пересечения — проекция компонентов K16 в компоненты K11).



















































Для отправки комментария необходимо войти на сайт.